AIP监控数据分析系统¶
系统简介¶
SkyForm AIP资源和作业管理调度系统常用于运行和调度模拟、分析、人工智能等应用和作业。 为了确保系统自动根据配置分配资源、用户作业运行正常及集群资源的充分利用, 图形化的监控,报告和分析工具是必备的。 而传统的关系型数据库和数据仓库工具不足以高速地处理作业调度管理系统生成的大数据量, 尤其是在系统中存在大量活动作业的情况下。
利用现代开源数据处理和可视化分析工具的优势,天云软件开发的SkyForm AIP监控系统是针对大型集群作业环境的作业负载监控、报告和分析软件。该监控系统具有活动的仪表盘, 灵活的数据,可视化和可定制的数据分析,让用户能够轻松地产生报表以检测服务质量和规划未来的 容量增长。
安装¶
安装前准备¶
在开始安装SkyForm AIP监控系统前,请先做好以下准备工作:
获取安装包
Elasticsearch v8/v9、Grafana v11/v12、Kibana v8/v9安装包,可到elastic.co和grafana.com官网下载
确保所有机器间能够通过DNS,NIS或/etc/hosts使用主机名互相通信。
Elasticsearch机器可以不是集群中的机器,但是必须能够被SkyForm AIP机器所访问。建议您将Elasticsearch安装在专门的主机上, 以保证Elasticsearch具有足够的资源提供服务。
Elasticsearch机器上需要安装Java run time environment,安装JRE:
yum install java
定义数据记录的时间间隔。
默认情况下所有数据的记录间隔为30秒。对于某些环境,比如有1000个主机,尤其是当作业平均时间为30分钟的环境,间隔为30秒可能太短,因为这样会有大量的数据被记录。
数据记录间隔在/opt/skyformai/etc/olmon.conf文件中定义 olmon.conf ,相关变量及其含义如下表所示。
变量 |
描述 |
默认值 |
|---|---|---|
job_update_interval |
更新不在作业 事件文件中的作业信息的时间间隔。 |
30秒 |
host_update_interval |
收集和主机信息的时间间隔。 在大规模的环境中,数据量会很大。 |
30秒 |
re source_update_interval |
采集共享资源数据的时间间隔。 |
30秒 |
rusagep reason_update_interval |
记录作业等待原因和作 业的资源使用情况数据的时间间隔。 |
60秒 |
log_duration |
数据收集时长(天)。仅最近一个收 集时长内的数据被保存在数据库中。 |
90天 |
eshosts |
定义安装Elasticsearch的 主机名,如:eshosts=host1,host2 |
|
grafana |
安装Graf ana的主机名或IP地址,web用户必须 能以这个地址或主机名访问到该主机 |
|
kibana |
安装Kib ana的主机名或IP地址,web用户必须 能以这个地址或主机名访问到该主机 |
|
job_index |
是否在ES index jobs里保存作业详细数据 |
1(是) |
安装Elasticsearch,Kibana,Grafana¶
SkyForm AIP的监控系统只支持Elasticsearch/Kibana 7.x和8.x。用户可直接从elastic.co官网下载最新的Elasticsearch和Kibana,从grafana.com下载 最新版的grafana (如v11)。
在所有规划好的Elasticsearch机器上安装Elasticsearch:
yum -y install ./elasticsearch*.rpm
或者:
dpkg -i ./elasticsearch*.deb
在所有Elasticsearch机器上安装Elasticsearch RPM或DEB后,修改文件/etc/elasticsearch/elasticsearch.yml,配置和添加以下内容 (假设Elasticsearch安装在host1、host2、和host3:
cluster.name: aip node.name: ${HOSTNAME} network.host: 0.0.0.0 discovery.seed_hosts: ["host1","host2","host3"] cluster.initial_master_nodes: ["host1","host2","host3"] # 关闭xpack xpack.security.enabled: false/etc/elasticsearch/jvm.options,配置JVM的可用内存,最佳时间为主机内存的一半。 如主机内存为8G,则设置4G(原来文件中设的是1G)。生产环境中最少设成4G以上:
-Xms4g -Xmx4g
在每台Elasticsearch机器上启动Elasticsearch服务:
systemctl enable --now elasticsearch
在某一台Elasticsearch机器上安装Kibana服务,例如选择第一台Elasticsearch机器安装。
yum -y install kibana*.rpm # 或 dpkg -i kibana*.deb
修改Kibana配置 /etc/kibana/kibana.yml:
# 允许所有机器都可以访问Kibana server.host: “0.0.0.0” # 把语言设成中文: i18n.locale: "zh-CN"
启动Kibana服务:
systemctl enable --now kibana
等待2-3分钟的Kibana初始化,然后用浏览器连接

选择Explore on my own。
在某一台Elasticsearch机器上安装Grafana服务,例如选择第一台Elasticsearch机器安装。
yum -y install grafana*.rpm # 或 dpkg -i grafana*.deb
配置Grafana,编辑/etc/grafana/grafana.ini:
[users] default_theme = light [security] allow_embedding = true [auth.anonymous] enabled = true
启动Grafana服务:
systemctl enable --now grafana-server
备注
以下的操作中,工具使用用户名admin和密码admin部署和提取Grafana里的dashboard。 用户admin的密码若修改会影响工具upload_grafana_dbs和download_grafana_dbs的使用。
建议您在Elasticsearch机器及Kibana/Grafana机器上均关闭防火墙。
安装数据采集服务(data collector)¶
警告
数据采集服务(data collector)需要安装在SkyForm AIP集群的master上。
安装步骤如下:
安装数据采集服务
数据采集服务所需的文件已经安装在SkyForm AIP所使用的共享文件系统里,如/opt/skyformai/monitor。
运行安装脚本:
cd /opt/skyformai/monitor
./installservice
在$CB_ENVDIR目录下修改配置文件olmon.conf。 可以拷贝/opt/skyformai/etc/olmon.tmp的内容, 然后修改。参数可以参考 安装前准备 的说明。添加至少以下内容:
eshosts=host1,host2,host3 log_duration=90 kibana=192.168.20.70 grafana=192.168.20.70
其中:
eshosts:Elasticsearch机器的主机名,以逗号(,)分隔 (以上以Elasticsearch主机名为”host1”、“host2”、和“host3”为例)。
log_duration:数据保留最长天数。若想保留时间长,则Elasticsearch 里的数据量会非常大,磁盘一旦满,数据就会出错。可以通过延长数据采集间隔减少数据量。
缺省是每30秒采集一次,建议添加以下变量减少采集频率(如180秒一次):
job_update_interval=180 host_update_interval=180 resource_update_interval=180
kibana:Kibana机器的IP
grafana:Grafana机器的IP
警告
不要在此文件中配置的主机名或IP后填写注释类信息, 如“kibana=192.168.20.70 # kibana server IP”等,否则可能会影响主机名或IP的解析。
检查安装是否成功。
确保作业调度管理系统中有正在运行的作业。
在前台运行数据采集服务,设置参数为“-2”。运行后等待一段时间直至显示 data/stream/cb.stream.0文件被打开,然后输入Ctrl-C退出。
执行以下命令:
/opt/skyformai/sbin/olcol -2
输出例子:
2024-05-08 13:39:38 109633 GB/memory unit=1048576.000000 2024-05-08 13:39:38 109633 olcol: started 2024-05-08 13:39:38 109633 Host query started 2024-05-08 13:39:39 109633 Shared resource query started 2024-05-08 13:39:39 109633 readevents: start to read file /opt/skyformai/work/data/cb.data 2024-05-08 13:39:50 109633 readevents: processed 5000 lines 2024-05-08 13:39:50 109633 readevents: processed 10000 lines 2024-05-08 13:39:50 109633 readevents: processed 15000 lines 2024-05-08 13:39:53 109633 readevents: processed 20000 lines... 2024-05-08 13:40:07 109633 cb.data file completed 2024-05-08 13:40:07 109633 readevents: start to read file /opt/skyformai/work/data /stream/cb.stream.0 2024-05-08 13:40:07 109633 readevents: processed 5000 lines 2024-05-08 13:40:08 109633 Job query started ^C
启动olmon服务:
systemctl start olmon
查看日志文件/opt/skyformai/log/olmon.log中是否有错误信息产生。
配置应用许可证使用数据采集¶
Olmon服务利用aip命令采集应用许可证服务。
配置aip命令许可证服务采集。编写$CB_ENVDIR/lic.yaml配置文件,参考 lic.yaml 里的配置说明和例子。
配置olmon调用aip命令获取许可证使用数据。修改以下两个参数:
lmstat_path指向aip命令的路径。可以用 Linux命令 which aip 获得路径,然后配置到这个参数上。
license_update_interval数据更新间隔,缺省30秒。由于获取许可证数据的命令会对许可证服务器造成负载,这个间隔不宜太短,建议60-180秒为最佳。
例子:
license_update_interval=180 lmstat_path=/opt/skyformai/bin/aip
数据采集服务OLMON高可用¶
Olmon服务自动定期检测当前运行主机是否为集群master。如果不是,则不采集数据。
Olmon服务的高可用方案为:在所有AIP集群master的候选机上都安装olmon服务,一个时候只有当前为master的主机上的olmon采集数据,其他主机上的olmon 服务处于等待状态。当AIP master切换时,olmon检测到当前的主机为master,自动激活采集数据。
导入Kibana&Grafana配置¶
在运行olmon服务的主机上,运行php -m。确保输出含有yaml和json:
php -m | egrep "yaml|json"
json
yaml
若缺少,需要安装:
# EL7
yum -y install epel-release
yum -y install php-pecl-yaml
# EL8
wget https://skyformaip.com/aip/php-yaml.el8.x86_64.tar.gz
tar xfz php-yaml.el8.x86_64.tar.gz -C /
dnf -y install php-json
# EL9, EL10
dnf -y install php-yaml
运行以下命令使Kibana能从Elasticsearch中获取数据:
cd /opt/skyformai/monitor ./upload_kibana_conf
然后在Kibana页面上(http://kibana主机:5601),选择左上方的菜单(三横线), 然后选择Analytics里的Dashboards。
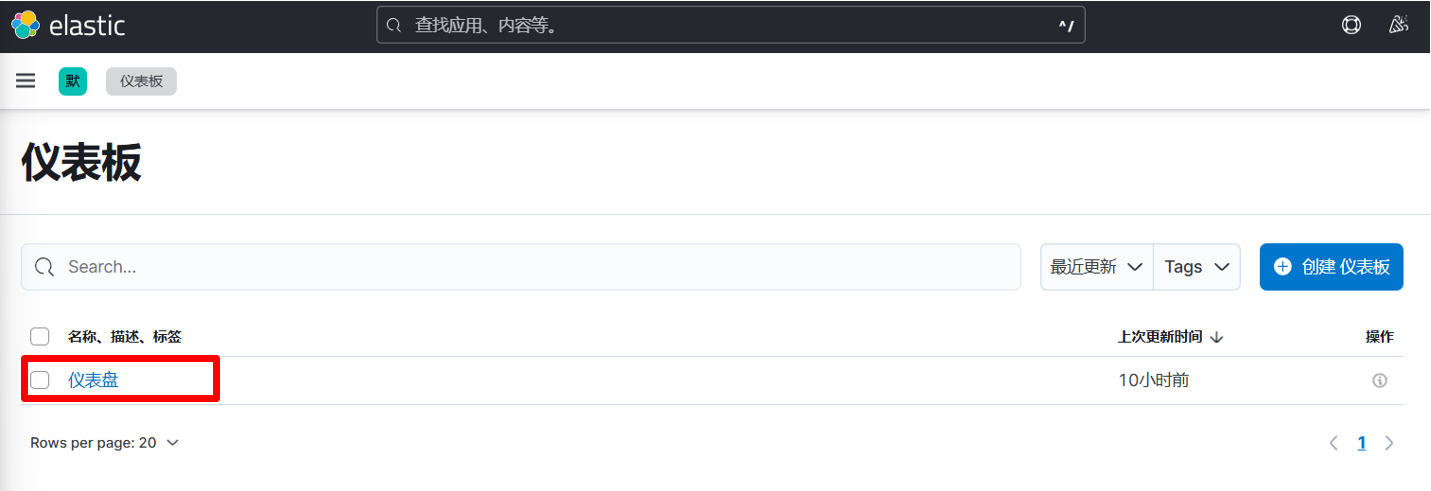
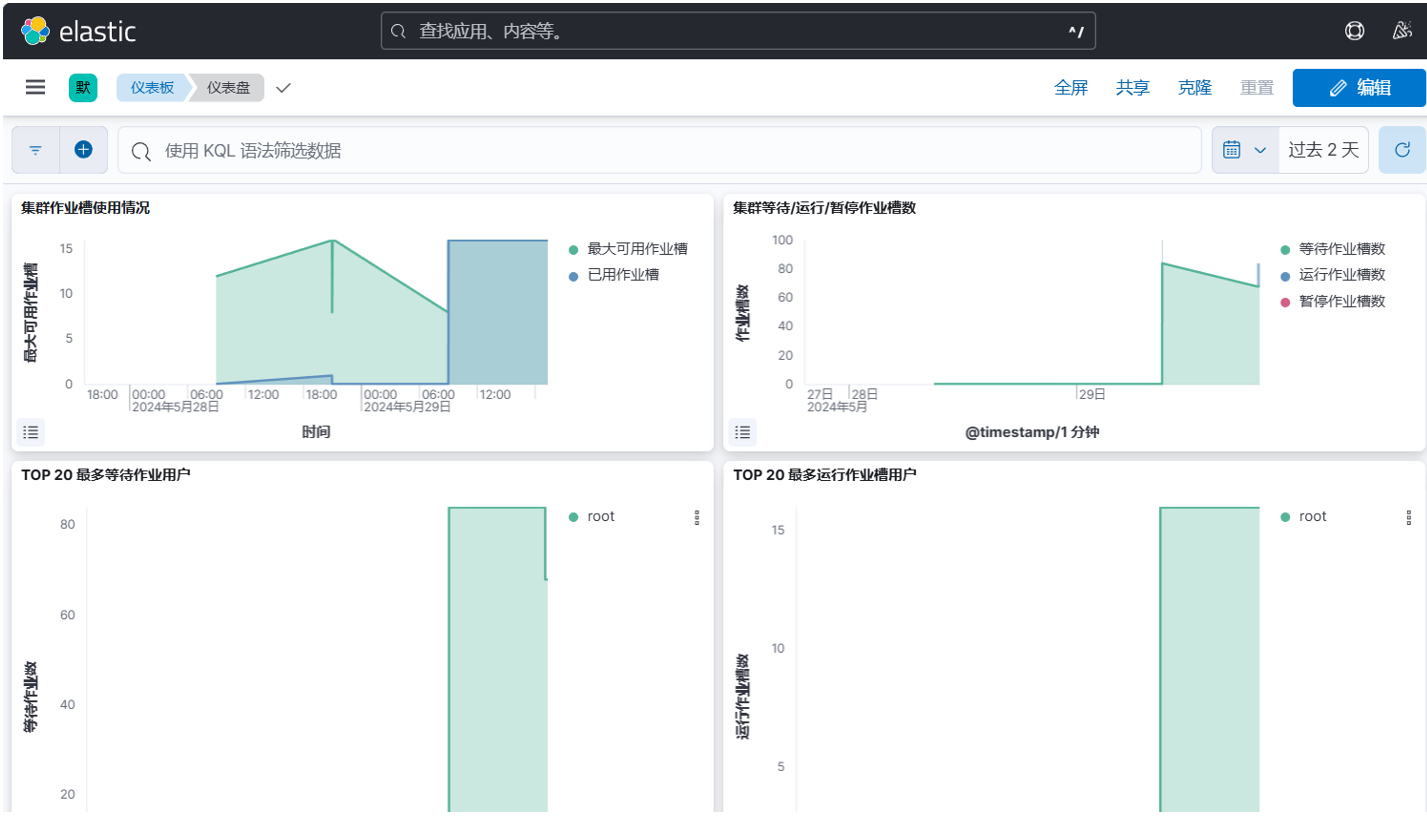
您将会看到Kibana已配置的仪表盘。
运行以下命令配置Grafana仪表盘:
./upload_grafana_dbs
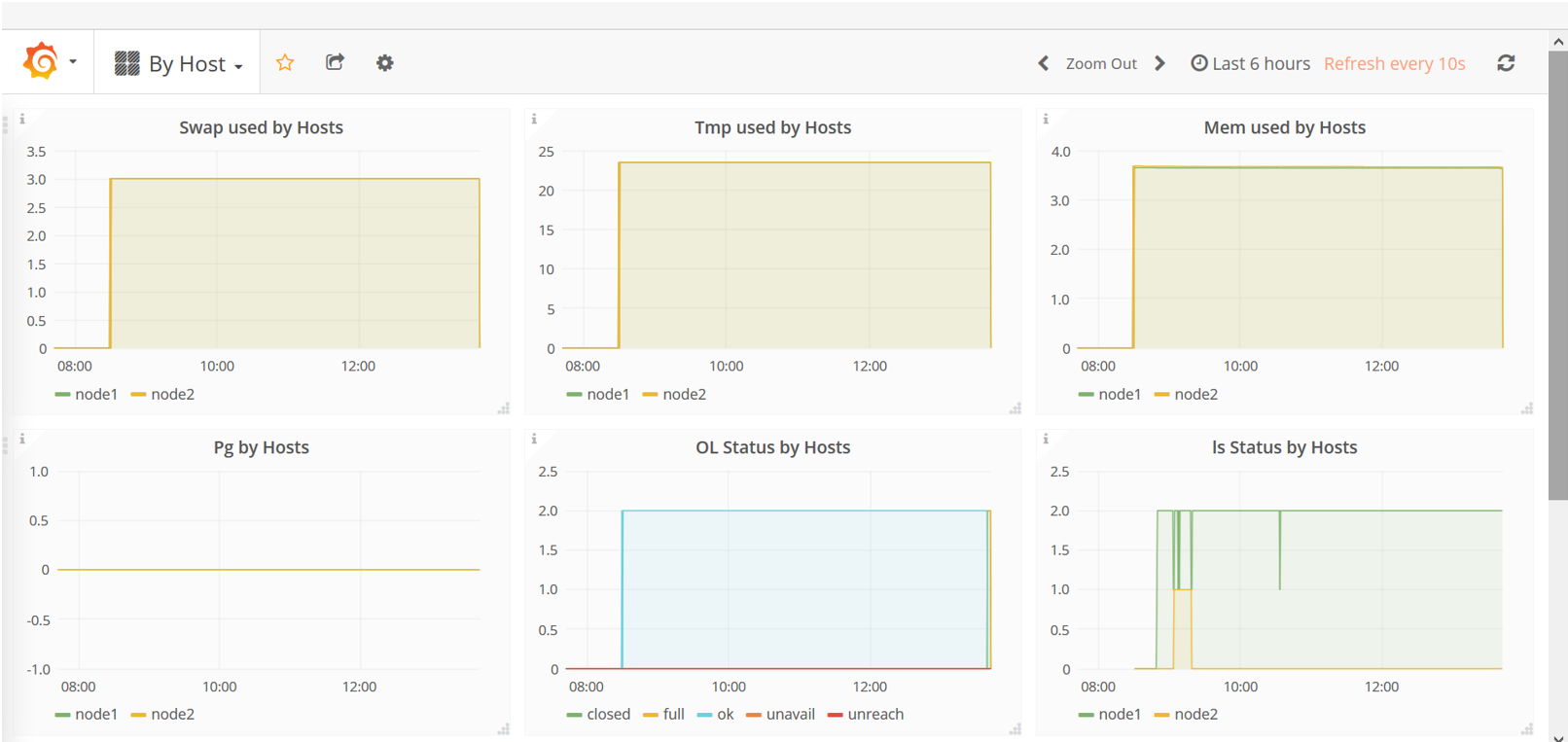
在浏览器中输入http://<grafana_host>:3000访问Grafana GUI。点击左上角的Home,将展示所有可显示的仪表盘。
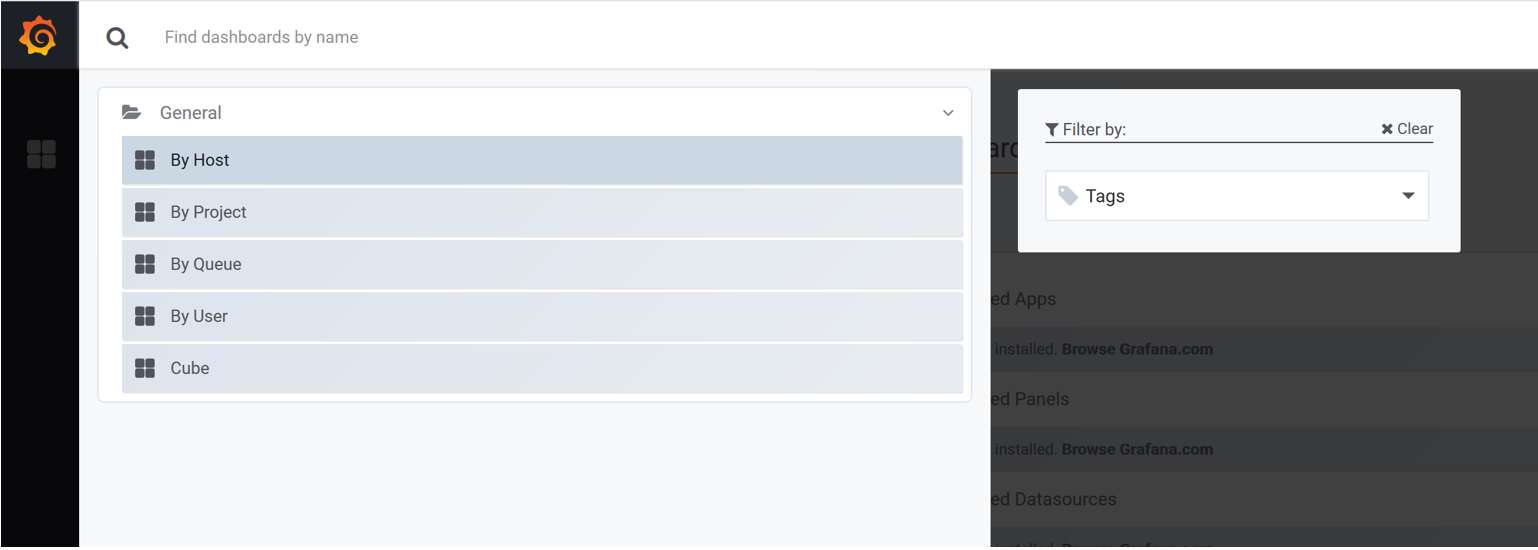
选择一个要查看的仪表盘。
与AIP门户的集成¶
参考 集成AIP监控数据分析系统 。
维护和定制¶
修改olmon.conf时间参数后重新导入Kibana&Grafana配置¶
在olmon服务运行一段时间后,而olmon.conf里的时间参数修改了,Kibana和Grafana里的图表配置必须修改。Vision提供了工具帮助自动修改Kibana和Grafana里配置的时间间隔参数。
导出配置:
cd /opt/skyformai/monitor ./download_kibana_conf ./download_grafana_dbd
小技巧
若你修改和定制了Kibana和Grafana的图表,这个工具也可用于备份Kibana和Grafana的所有配置。
重新导入:
./upload_kibana_conf ./upload_grafana_dbs
在jobs和users-time索引中增加外插用户组织信息¶
通过运行外部命令(如数据库访问等方式)获得用户的额外信息,如组织关系, 可以选择插入到jobs和users-time索引的数据中。
配置方法如下:
在olmon.conf里配置两个参数:
user_data_cmd = 可执行文件的全路径
这个可执行文件(如脚本)执行后的输出格式为:
第一行:需要插入的索引名,如”jobs users-time”
第二行:数据名,多项用空格隔开,如“tenant dept”
第三行起,每行一个用户数据,格式为:用户名,数据值,如”u001 skyform dev”,其中skyform为tenant的值,dev为dept的值。Olmon自动把以下内容插入索引中用户名为u001的记录中:tenant: skyform, dept: dev
可执行文件命令(脚本)输出例子:
users-time tenant dept u001 skyform dev u002 skyform consult u003 simforge test u004 simforge test2
user_data_interval = 更新间隔(olmon服务运行以上脚本的间隔),单位为秒。 缺省为一小时,3600秒。
例子:
user_data_interval = 300
故障排查¶
Elasticsearch数据写入¶
数据采集系统服务每分钟监控数据采集进程一次。如果它发现一些进程死掉,会重新启动它。
当有数据写入Elasticsearch错误时,请查看以下文件进行故障定位或将其发送给技术支持人员:
监控系统数据采集器主机上的/opt/skyformai/log/putbody-时间戳.txt文件。
Elasticsearch的日志文件在Elasticsearch主机的/var/log/elasticsearch目录下。
Elasticsearch数据读取例子¶
假设host-times的数据更新间隔(host_update_interval)为60秒,读取最近一次的所有主机监控数据:
curl -XPOST -s 'http://eshost:9200/hosts-time/_search?size=30000' \
-H "Content-Type: application/json" \
-d '{"query":{"range":{"@timestamp":{"gt": "now-1m"}}}}'
假设jobs-times的数据更新间隔(job_update_interval)为30秒,读取最近一次的所有运行作业 监控数据(最多50万个作业):
curl -XPOST -s 'http://eshost:9200/jobs-time/_search?size=500000' \
-H "Content-Type: application/json" \
-d '{"query":{"range":{"@timestamp":{"gt": "now-30s"}}}}'
数据说明¶
本章描述监控在Elasticsearch里存放的数据字段。每一节描述一个index。
jobs¶
Index 名:jobs (每个作业一条数据,随作业生命周期的时间而更新)。
{
"cluster": "aip", # 集群名
"@timestamp": "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
"jobId": 225, # 作业号
"options": 33554435, # aip内部使用
"numProcessors": 1, # 作业请求的最小CPU核数
"submitTime": "2020-09-05T21:28:23.000-05:00", # 作业提交时间,本地时区
"submitTimeUTC": 1599355703, # 作业提交时间戳
"beginTime": "", # 作业提交请求开始运行时间,空:未定义
"beginTimeUTC": 0, # 作业提交请求开始运行时间戳,0:未定义
"termTime": "", # 作业提交请求结束运行时间,空:未定义
"termTimeUTC": 0, # 作业提交请求结束运行时间戳,0:未定义
"userName": "u003", # 作业提交用户名
"rLimits": [ # 作业提交进程资源限制参数表(详见getrlimit(2)
# 或ulimit)-1表示无限或用aip服务运行的缺省设置
#(/opt/skyformai/etc/limits.sh)
-1, # CPU时间限制(秒)
-1, # 生成文件大小限制
-1, # 使用数据(data segment)大小限制
-1, # 使用堆栈(stack segment)大小限制
-1, # 生成core文件大小限制
-1, # 内存使用限制
-1, # 未来预留
-1, # 未来预留
-1, # 未来预留
-1, # 运行时间限制
-1 # 未来预留
],
"hostFactor": 61.9, # 作业提交主机的CPU 性能参数
"queue": "medium", # 队列名
"resReq": "", # 作业提交资源需求定义字串(详见csub(1) -R参数)
"memReq": 0, # 提交内存预留值(GB)
"fromHost": "aip-master", # 作业提交主机名
"cwd": "/root", # 作业请求运行工作路径
"inFile": "", # 标准输入(stdin)文件
"outFile": "", # 标准输出(stdout)文件
"errFile": "", # 标准错误输出(stderr)文件
"subHomeDir": "/home/u003", # 作业提交用户home目录
"numAskedHosts": 0, # 提交时指定作业运行主机数
"askedHosts": [], # 提交时指定作业运行主机名阵列
"dependCond": "", # 作业依赖定义(详见csub(1) -w参数)
"preExecCmd": "", # 作业预处理程序路径(csub(1) -E)
"command": "/bin/sleep 227", # 作业命令行
"mailUser": "", # 作业提交指定邮箱通知的邮箱用户名
"projectName": "default", # 项目名
"interact": 0, # 终端交互作业 0: 否,1:是
"maxNumProc": 1, # 提交请求最大CPU核数
"loginShell": "", # 指定的作业运行登录shell,空为不用登录shell运行作业
"options2": 5136, # AIP内部使用
"userPriority": -1, # 用户定义的作业优先级,-1:未定义
"userGroup": "", # 指定作业用户组,空:未定义
"jobGroup": "", # 作业所属作业组,空:未定义
"jobDesc": "", # 作业描述字串,空:未定义
"status": "PEND", # 当前作业状态。详见在线文档cjobs 描述
"startTime": "", # 作业开始运行时间,本地时区,空:尚未开始运行
"endTime": "", # 作业结束运行时间,本地时区,空:尚未结束运行
"numExHosts": 0, # 运行占用作业槽数(CPU核数)
"execHosts": [], # 运行作业槽对应的主机名阵列
"reason": 0, # 作业等待或暂停原因内部参数,可调用AIP C API
# cbSuspReason()或cbPendReason()解析
"subreasons": 0, # 作业等待或暂停原因内部参数,可调用AIP C API
# cbSuspReason()或cbPendReason()解析
"jRusageUpdateTime": 0, # 最近作业资源使用情况更新时间戳
"pendReasons": " New job is waiting for scheduling: 1 host;^",
# 作业等待原因解析结果
"suspReasons":"", # 作业暂停原因解析结果
"mem": 0, # 当前作业内存使用量(MB)
"memEfficiency": 0.23, # 当前作业最大内存/请求内存
"stime": 0, # 作业运行所用系统CPU时间(秒)
"utime": 0, # 作业运行所用用户CPU时间(秒)
"swap": 0, # 作业运行交换区用量(MB)
"pidInfo": [ # 作业所属的进程号和进程组号
"pid": [], # 作业的所有进程号
"pgid": [], # 作业进程对应的进程组号
"ppid": [] # 作业进程对应的父进程号
],
"execCwd": "", # 作业运行工作路径
"maxMem": 0, # 作业运行最大内存用量(MB)
"avgMem": 0, # 作业运行平均内存用量(MB)
"alloc": "", # 调度器为作业分配的资源JSON串,包括主机、CPU、GPU、端口等
"taskInfo": [], # 子任务(使用AIP分发远程MPI子任务或分布式深度学习作业)
# 的资源使用
"jobName": "test[108]", # 作业名
"idx": 108, # 作业阵列index
"cpuUsage": 0.01, # 作业CPU利用率0 - 1代表0 -100%
“runtime”: 0, # 作业运行时间(秒)
“idle”: false, # 当队列配置了job_idle参数后作业限制检测
“msg”: 0, # 最后作业消息的发布时间戳
“content”: "", # 最后的作业消息内容
“exitStatus”: 0, # 作业退出码
“exitStatusString”: "", # 作业退出exit code或者退出时接受到的signal,
# 值为:“Exit Code xxx”,或“By Signal xxx”,
# xxx为整数
“exitReason”: "", # 作业异常退出的原因说明
“nthreads”: 0, # 总线程数
“app”: "" # 作业提交时-A参数定义的应用名
}
jobs-time¶
Index名:jobs-time (每job_update_interval每运行作业一条数据)
{
"cluster": "aip", # 集群名
"@timestamp": "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“jobId”: 225, # 作业号
“idx”: 108, # 作业阵列index
“queue”: “medium”, # 队列名
“cpu”: 0.12, # 作业CPU用时(秒)
“mem”: 0.12, # 作业所用内存GB
“swap”: 0.23, # 作业交换区使用GB
“nthreads”: 2, # 作业线程数
“io”: 23, # 作业存储IO率KB/秒
“gmem”: 4, # 作业所用GPU内存MB
“user”: “cadmin”, # 作业所属用户名
“project”: “default”, # 项目名
“descript”: “”, # 作业描述名
“slots”: 4, # 作业占用槽数
“host”: “linux” # 作业运行第一台主机名
“cpuUt”: 0, # 作业整个运行的CPU利用率(0-1表示0-100%)
“smpl_cpuut”: 0.98, # 作业在过去一个采样点的CPU利用率(0-1表示0-100%)
“ugroup”: “test”, # 作业从属的第一个用户组名
“ps”:[{ # 作业进程详情
“host”: "linux", # 作业进程运行主机名
“pids”: [{ # 主机上的所有该作业进程
“pid”: 111, # 进程号
“pgid”: 111, # 进程所属组号
“cput”: 0, # CPU 用时(秒)
“mem”: 0, # 内存使用量MB
“swp”: 0, # 交换区使用量MB
“nthrds”: 3, # 进程所含线程数
“diskrd”: 0.3, # 进程存储读速率KB/秒
“diskwr”: 0.5, # 进程存储写速率KB/秒
“gmem”: 0, # 进程GPU内存用量MB
“cmd”: "(sleep)" # 进程命令
}]
}]
}
hosts-time¶
Index名:hosts-time (每host_update_interval每主机一条数据)
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“cluster”: "aip", # 集群名
“name”: "linux", # 主机名
“status”: "Ok", # 主机状态(详见在线文档chosts描述)
# Ok: 良好
# Unavail: AIP服务异常
# Unreach: 作业服务cbjm异常
# Closed-Admin: 主机被管理员关闭
# Closed-Excl: 主机被独占作业占用
# Closed-Full: 主机所有作业槽都被占用
# Closed-Busy:主机负载超过所设阈值
“hgroup”: "", # 主机所属主机组名
“queues”: ["medium","high"], # 主机所属队列名列表
“maxJobs”: 56, # 主机作业槽上限
“numJobs”: 3, # 运行、暂停、和保留的作业槽总数
“numRUN”: 3, # 运行作业槽数
“numSSUSP”: 0, # 被系统暂停(如过载)的作业槽数
“numUSUSP”: 0, # 用户或管理暂停的作业槽数
“numRESERVE”: 0, # 调度器为大作业预留的作业槽数
“maxMem”: 100, # 主机最大可用内存GB
“memUt”: 0.3, # 包含作业预留的内存使用率(0-1代表0-100%)
“realmemUt”: 0.4, # 实际内存使用率(0-1代表0-100%)
“maxSwap”: 2, # 最大可用SWAP GB
“swapUt”: 0.1, # SWAP使用率(0-1代表0-100%)
“slotUt”: 0.054, # 作业槽使用率(0-1代表0-100%)
“r15s”: 0, # CPU进程队列15秒平均
“r1m”: 0, # CPU进程队列1分钟平均
“r15m”: 0, # CPU进程队列15分钟平均
“ut”: 0.1, # CPU平均使用率(0-1代表0-100%)
“mem”: 90, # 可用内存GB
“swp”: 1.2, # 可用SWAP GB
“up”: 13456, # 正常运行时间(秒)
“it”: 0, # 空闲时间(秒)
“tmp”: 45, # /tmp可用存储GB
“usedMem”: 12, # 已用内存GB
“reservedMem”: 10, # 作业预留的内存GB
“gpu”: 1, # 可用gpu卡数
“pg”: 0, # paging rate (page/sec)
“io”: 0, # 网络IO KB/秒
“cpus”: [{ # CPU核利用率
“id”: 0, # CPU核ID
“ut”: 0.1}], # 核利用率(0-1代表0-100%)
“gpus”: [{ # GPU监控
“id”: 0, # GPU卡号
“model”: "GTX3090", # GPU型号第2个以后的字段(如Tesla M60为M60)
“maxmem”: 15098, # GPU最大显存MB
“mem”: 15020, # GPU可用显存MB
“usage”: 0, # GPU作业分配律(0-1代表0-100%)
“gut”: 0, # GPU真实利用率(0-1代表0-100%)
“memUt”: 0, # GPU显存利用率(0-1代表0-100%)
“temp”: 21}], # GPU温度(摄氏)
“nic”: [{ # 网络设备IO
“device”: "eth0", # 设备名
“recv”: 0, # 接收数据KB/秒
“send”: 0}], # 送出数据KB/秒
“diskio”: [{ # 本地存储设备IO
“device”: "sda", # 设备名
“read”: 0, # 读取数据KB/秒
“write”: 0}], # 写入数据KB/秒
“pids”: [{ # 作业相关进程监控
“pid”: 9090, # 进程号
“pgid”: 9090, # 进程所属组号
“cput”: 3, # CPU 用时(秒)
“mem”: 123, # 内存使用量MB
“swp”: 34, # 虚拟内存使用量MB
“nthreds”: 1, # 进程所含线程数
“diskrd”: 0, # 进程存储读速率KB/秒
“diskwr”: 0, # 进程存储写速率KB/秒
“gmem”: 0, # 进程GPU内存用量MB
“jobid”: 122, # 进程所属作业号
“idx”: 0, # 进程所属作业阵列号(非阵列作业为0)
“user”: "u001"}] # 所属用户
}
hgroups-time¶
Index名:hgroup-time (每host_update_interval每主机组一条数据)
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“cluster”: "aip", # 集群名
“name”: "cad", # 主机组名,主机组名为_allhosts代表整个集群
“members”: ["node01","node02"] # 主机组成员列表
“availSlots”: 23, # 主机组可用作业槽数
“maxAvaliSlots”: 100, # 主机组最大可用作业槽数
“availMemGB”: 453, # 主机组可用内存总和(GB)
“maxAvailMemGB”: 543, # 主机组最大可用内存总和(GB)
“cpuUT”: 0.3, # 主机组主机CPU权重利用率(0-1 代表0-100%),利用率根据主机总核数进行权重
备注
主机组名为 _allhosts 为整个集群的指标。
users-time¶
Index名: users-time (每rusagepreason_update_interval每用户每队列一条数据)
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“user”: "cadmin", # 用户名
“queue”: "medium", # 队列名
“numRUN”: 2, # 该用户在该队列中运行作业总槽数
“numPEND”: 100, # 该用户在该队列中等待作业总槽数
“numSUSP”: 0, # 该用户在该队列中暂停作业总槽数
“jobRUN”: 1, # 该用户在该队列中运行作业总数
“jobPEND”: 50, # 该用户在该队列中等待作业总数
“jobSUSP”: 0, # 该用户在该队列中暂停作业总数
“cluster”: "aip" # 集群名
}
preasons-time¶
Index名:preasons-time (每rusagepreason_update_interval每个原因一条数据)
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“reason”: "New job", # 作业等待原因
“counter”: 2, # 该等待原因的作业数
“cluster”: "aip", # 集群名
“queue”: “medium” # 队列名
}
shres-time¶
Index名:shres-time (每resource_update_interval每种共享资源一条数据)。共享资源由RESS提供,主机级的RESS参数在hosts-time的每个主机的数据中。
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“cluster”: "aip", # 集群名
“name”: "proxy", # 资源名
“value”: 100, # RESS上报的值
“rsvValue”: 39 # 被作业占用的值
}
queues-time¶
Index名:queues-time (每job_update_interval每个队列一条数据)。
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“cluster”: "aip", # 集群名
“name”: "medium", # 队列名
“priority”: 3, # 队列优先级
“status”: "Ok", # 队列状态: OK, Open:Inactive, Closed:Active,
# Closed:Inactive,参考cqueues
“userJLimit”: -1, # 每个用户的作业槽上限
“availGPUs”: 1, # 队列可用GPU数
“maxAvaliGPUs”: 1, # 队列最大可用GPU数
“availMemGB”: 453, # 队列可用内存总和(GB)
“maxAvailMemGB”: 543, # 队列最大可用内存总和(GB)
“cpuUT”: 0.3, # 队列主机CPU权重利用率(0-1 代表0-100%),利用率根据主机总核数进行权重
“availSlots”: 23, # 队列可用作业槽数
“maxAvaliSlots”: 100, # 队列最大可用作业槽数
“maxJ”: -1, # 队列配置的作业槽上限
“nJobs”: 0, # 等待、运行和暂停的作业槽数
“nPend”: 0, # 等待作业所需作业槽数
“nStop”: 0, # 暂停作业所占作业槽数
“nRun”: 0 # 运行作业所占作业槽数
}
ugroups-time¶
Index名:ugroups-time (每rusagepreason_interval每个用户组一条数据)。
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“cluster”: "aip", # 集群名
“name”: "ug1", # 用户或用户组名
“maxJ”: -1, # 配置的用户可用作业槽上限
“nJobs”: 8, # 等待、运行和暂停的作业的作业槽数
“nPend”: 8, # 等待作业所需作业槽数
“nStop”: 0, # 暂停作业所占作业槽数
“nRun”: 0 # 运行作业所占作业槽数
}
licenses-time¶
ndex名:licenses-time (每license_update_interval每个Feature每个用户一条数据)。
{
“@timestamp”: "2020-09-06T01:28:23.000Z", # 数据更新时间,时区为UTC
“Server”: "14203@licserver", # 许可证服务器
“Service”: "Skyform", # 在lic.yaml里配置的服务名
“Vendor”: "skyform_lmd", # Vendor daemon的名字
“Feature”: "aip", # Feature名
“Total”: 13, # Feature许可总数
“Free”: 10, # Feature可用许可数
“Expiry”: "", # 许可到期时间,空表示永久
“User”: "u001", # 使用Feature的用户名
“InUse”: 1, # 以上用户使用的Feature许可数
“Version”: "v1.000" # Feature的版本号
}
updatetime¶
Index名:updatetime 除jobs外各个index数据最后更新的时间
{
“index”: "ugroups-time", # index名,如jobs-time
“last_update”: "2020-09-06T01:28:23.000Z" # 最近一次数据更新时间UTC
}
log-daemon名-master主机名¶
Index名:log-daemin名-master主机名 调度器主控(master)主机上daemon的日志。每个 olmon.conf 中 logfile配置的daemon名字一个index
{
"@timestamp": "2025-02-01T23:38:28.000Z", # 日志时间戳,时区为UTC
"cluster":"aip", # 集群名
"loglevel": "ERR", # 日志级别
"version": "10.25.0", # 调度器版本
"process": "2947471", # daemon进程号
"function": "main", # 产生日志的C函数(function)名
"message": "main: CBSCHED is started" # 日志内容
}
警告
AIP以前版本的日志中没有年份,日志上传时olcol程序会自动加入当前年份,老的日志的年份可能是错误的。 最佳实践是删除老版本AIP的日志文件后再启动olmon服务。